 Là ça y est, Google est vraiment vexé.
Là ça y est, Google est vraiment vexé.
Matt Cutts et son équipe responsable de combattre le spam ont pris dans les dents les critiques récentes à propos de la domination du moteur de recherche par les spammeurs, référenceurs et webmarketeurs.
Sauf que la cible de choix se tourne encore et toujours vers les spammeurs, laissant croître les saloperies de contenu qui ne valent pas un clou.
Le discours sur le spam et Google n’est pas neuf. Par contre, 2011 a l’air d’avoir affirmé le constat d’incapacité latente pour le moteur de combattre ce qu’il considère comme de la pollution.
Pan dans les dents
Quand des ténors du référencement tels que SEOMoz évoquent ce constat, Matt Cutts fait « gloup », lorsqu’un blog majeur comme ReadWriteWeb roucoule, ça hérisse les cheveux de toute l’équipe antispam, mais quand c’est carrément le Washington Post qui sonne la charge, alors ça fait vraiment tâche sur toute l’entreprise Google. Avec le fondateur historique, Larry Page, qui prend les rênes de CEO, j’ose penser qu’il y a eu remontée de bretelles. En réponse, Matt Cutts nous sert un post sur le blog officiel, puis enchaîne avec un update d’algorithme.
Plus près de nous, l’insatiable Sylvain nous décline les maux attribués au référenceur ; ce qui m’a inspiré d’extrapoler sur mon commentaire au travers de ce billet.
A Lire également le dossier sur Webrankinfo : les changements de l’algorithme Google depuis 1 an.
Black Hat SEO et AFP Rewriting, même combat
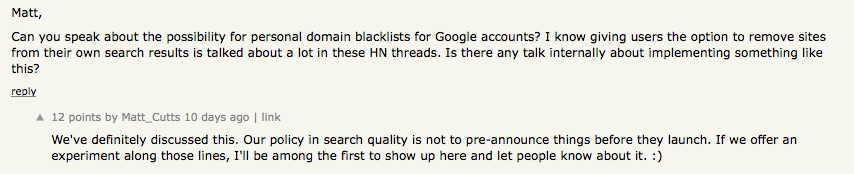
En parallèle à ces affronts médiatiques, le moteur Blekko fait parler de lui. La mise en évidence de la « propreté » des résultats de recherche comparés à ceux de Google fait obligatoirement grincer des dents du côté de Mountain View. On peut en lire la trace évidente dans cette discussion sur Hacker News où Matt Cutts évoque la possibilité d’avoir un Blekko Like sur Google.
Pour couronner le tout, l’entrée en Bourse de Demand Media, société éditrices de fermes de contenu, évoque des sourires narquois sur la possibilité de générer des fortunes en publiant du contenu bas de gamme.
C’est ce dernier point qui me préoccupe car le dernier update vise apparemment le scraping de base (Note : je n’ai pas encore ausculté cet update en profondeur), laissant la place au contenu de merde qui est toujours aussi bien valorisé par le moteur.
D’après les statistiques internes à Google, le spam serait en recul… sauf qu’on n’a pas vu ses données.
Le problème est que du petit bout de notre lorgnette, rien n’a changé.
Matt Cutts peut bien faire des effets d’annonce avec un update lâché à la hâte, ça n’enlèvera pas que les paramètres « off page » seront toujours quasiment impossibles à combattre.
Je m’explique…
Depuis toujours, Google a focalisé son combat sur le contenu caché, généré automatiquement, etc. Ce sont des éléments « on page » sur lesquels les progrès sont sensibles ; même si le volume permet encore d’obtenir des résultats. La stratégie reste identique, mais la méthodologie a sensiblement évolué.
Avant, il suffisait, par exemple, de mélanger des flux RSS (Yahoo! Pipes est fabuleux pour faire cela) ou scraper de manière basique 2 ou 3 pages pour fabriquer un contenu soi-disant unique.
En plus du scraping, le spinning consiste à prendre un texte et mélanger les phrases. Aujourd’hui, je dissocie cette notion de spinning avec le morphing qui consiste à introduire des variables sur certains mots clés (voir aperçu ci-dessous extrait du mode d’emploi de Xrumer).

Une autre méthodologie intéressante tend à traduire automatiquement des textes. Sauf que le résultat est toujours une bouillie infâme de mots si on ne prend pas la peine de travailler avec des dictionnaires customisés et plus.
Il y a juste une parade qui consiste à corriger la traduction automatique ; c’est bien moins couteux que créer du contenu à partir de 0 ; même s’il s’agit de paraphrase basique qu’on appellera AFP Rewriting en hommage aux innombrables sites d’infos qui se contentent de réécrire à la hâte des dépêches AFP ou autre.
Apparemment, le dernier update vise surtout les scrapers qui récupèrent du contenu sur diverses sources pour générer une soupe infâme. Franchement, ça ne n’impressionne pas de viser ce type de contenu en 2011. Surtout qu’il y a un paquet de sites qui sont pris dans la tourmente sans être concerné par cette technique.
Tout ça pour dire que les techniques visant à fourguer du contenu dans les moteurs évoluent. Combattre le spam de base n’est pas le problème ; c’est le contenu de basse qualité qui doit être la cible.
Le seul hic est que la vaste majorité du Web est de basse qualité.
J’ai trituré en long, en large et en travers des textes à base de morphing automatique ou de AFP Rewriting (paraphrase basique) effectuée à la main. Tous les résultats de Latent Semantic Analysis que j’ai tenté sont unanimes ; il n’y a pas ou très peu de différence entre le contenu généré automatiquement de manière subtile ou le contenu généré à la main de manière basique. Parfois, le contenu automatique obtient un meilleur score que le contenu rédigé à la main.
Ainsi, il faut voir que Google n’est pas sorti d’affaire s’il veut vraiment s’attaquer aux fermes de contenu et équivalent en termes de qualité rédactionnelle. Pour autant, le Web n’a pas vocation de contenir uniquement des écrits destinés à gagner le prix Pulitzer. A partir du moment où Google n’est pas un moteur sémantique, il ne comprend pas ce qu’il lit, la tâche n’est pas aisée pour la batterie d’algorithme et l’armée d’ingénieurs superstars. A priori, des sites appartenant au réseau Demand Media, comme ehow.com, pourraient servir d’exemple, mais l’AFP Rewriting ou le MFA (MadeForAdsense) est loin d’avoir rejoint le caveau.
Bon, reste aussi à évoquer la problématique du contenu dupliqué.
De ce côté, Google a fait d’énormes progrès pour gérer les URLs dupliquées sur un même site. Auparavant, on pouvait faire tomber une page simplement en générant des URLs dupliquées fantômes vers lesquelles des backlinks iront pointer.
Si j’en crois la dernière update, le problème du contenu partiellement dupliqué entre différents sites est en ligne de mire. Sans même parler de Black Hat SEO, c’est toujours inquiétant de voir pointer un agrégateur de flux RSS avant sa propre URL.
Jusqu’à présent, on pouvait toujours récupérer un texte déjà publié en ligne et faire sauter l’antériorité ; du moment qu’il y avait assez de backlinks pointant vers la nouvelle source. A voir si cela va toujours être possible.
C’est justement une transition parfaite pour mon point suivant qui est pour moi celui où Google reste coincé.
La loi du backlink
Un dicton du SEO dit « donne moi un titre et des backlinks avec anchor text adéquat et je te positionne une page sans contenu ».
Le pouvoir du lien entrant n’est pas à démentir. Après la balise TITLE, c’est pour moi le deuxième élément le plus important de tous les facteurs influents le référencement.
Les liens sont le sang du Web et Google n’existerait pas sans eux puisque c’est grâce au maillage entre les sites qu’il peut indexer le Web. Le concept même du PageRank est basé sur le transfert de popularité entre les pages qui sont liées.
Bref, le lien est vital, fondamental, indispensable.
Sauf que je ne suis pas forcément responsable des liens qui pointent vers mon site. C’est là le point crucial qui met Google dans une impasse. A partir du moment où il pénalisera un site à cause d’un profil de liens dégueulasse, nous ne ferons plus de référencement, mais simplement du déréférencement des concurrents. Si le site est irréprochable « on page » et donnons lui un profil de liens classique pour démarrer, comment Google peut le pénaliser s’il attire soudainement un afflux massif de liens avec une empreinte nette de Black Hat SEO ?
Le problème est de faire du crade « on page » et « off page » , mais si vous donnez de l’amour à votre site comme dit mon cher ami Tiger, vous avez énormément de latitude « off page ».
Mettons que vous souhaitez vous positionner sur un mot clef concurrentiel. Vous fabriquez vos pages pertinentes et tout. Après, vous entamez le travail de besogneux du netlinking à la main. Avec tout ça, vous arrivez en fond de première page après quelques semaines de travail. Par-dessus cette couche « propre », mettez les gaz en linking automatique avec Xrumer ou équivalent. De la sorte, il y a de fortes probabilités que vous arriviez à vos objectifs.
Le dernier update évoque ce paramètre en impliquant l’empreinte donnée par les commentaires typiquement classés comme du spam. Oui mais l’attribut nofollow n’était pas conçu pour éradiquer ce problème à la base ? C’est vrai, mais on voit bien que ce pétard mouillé est devenue une véritable farce ou plutôt une vilaine verrue. Enfin bon, lorsqu’on voit le potentiel des logiciels de linking automatique, viser l’empreinte de commentaires spammy donne l’impression d’une 2CV qui fait la course contre une Formule1.
Alors, Google coincé ?
Pour moi, le constat est sans appel par rapport à l’archi domination des spammeurs, référenceurs et webmarketeurs sur Google ; sans avoir des notions de référencement, dur de se faire une place au soleil.
Je vois mal le moteur effectuer un virage à 90% pour populariser autre chose que l’existant. Il pourra continuer de faire du fine tuning comme avec le dernier update, touchant 1 ou 2% des résultats de recherche au grand maximum, mais difficile de changer une équipe qui gagne. Sur le plan global, on ne peut nier que Google gagne encore et toujours. Les power users trouvent toujours à redire sur la qualité des résultats de recherche, mais l’internaute lambda est ravi puisqu’il trouve réponse à sa requête. D’ailleurs, la plupart du temps, il ne sait même pas que le site consulté est une ferme de contenu ou un racoleur commercial.
Le combat de Google peut être en apparence contre le vilain spam, mais les Black Hat SEO savent évoluer plus rapidement que les mises à jour d’algorithme. C’est comme cela depuis le début et rien ne changera à ce niveau.
Pour ce qui est du « on page », il faut devenir plus sophistiqué, mais rien de difficile à servir du contenu passable pour assouvir le glouton moteur. En ce qui concerne le « off page », j’attends de voir comment Google peut s’en sortir. Dévaluer la pondération du backlink semble la solution évidente, mais c’est l’algorithme de base (Google fonctionne avec un algorithme par couches) qui est touché. Ce dernier date de 1996 avec une refonte en 2001 ; ça serait un gros chantier pour revoir entièrement le système de pondération.
Dans mon titre, je suggère que le spam n’est pas le problème car les Black Hat SEO ou autre spammeurs ont déjà évolué dans la génération de contenu. Les indices récents de lutte donnés par Google s’attaquent encore à de vieux démons qui sont dépassés par l’arsenal d’aujourd’hui pour ceux qui évoluent du côté obscur de la Force. Le contenu de qualité médiocre est beaucoup plus difficile à contrer. A ce niveau, Google est loin du compte… très très loin…
Bref, on verra bien, mais en attendant je ne me fais pas la moindre illusion sur le vain combat de Google contre le spam et surtout contre le contenu de basse qualité.
Tiens c’est bizarre mais ton billet je l’attendais!!!
Je pense qu’un point de vu serait intéressant à aborder. Celui des BH.
Car ils utilisent « le contenu de faible qualité » à tour de bras.
Donc s’ils pouvaient nous dire s’ils ont vraiment vu leurs sites bouger.
On saurait si GG et sa modif d’algo a atteint la cible.
Franchement j’y crois pas pour un sou, à mon avis on aura plus de dommages collatéraux que de sites réellement punis et méritant.
Il prendra encore une fois qq gros sites très visibles pour donner l’exemple en clamant haut et fort vous voyer on peut le détecter alors trembler.
Tout a fait d’accord avec toi, je vois mal comment Google pourrait rivaliser contre toutes ces techniques (Black Hat,…). Il aura toujours une guerre de retard.
Article très intéressant, Google a en effet atteint ses limites niveau spam, dans la mesure où, comme tu le dis si bien : « je ne suis pas forcément responsable des liens qui pointent vers mon site » !
Quant au déréférencement, ça existe déjà, pour les jeunes sites de concurrents, il n’est pas compliqué de les faire blacklister !
Merci, j’approuve à 100% ton article. Je ne vois pas moi non plus comment Google pourrait efficacement combattre les fermes de contenu. Le Spam a encore de longs jours devant lui chez Google, n’en déplaise à certains SEO qui pensent que c’est mort (encore une fois…) Les SEO bisounours doivent se recycler…
@RaphSEO : d’après mon tour des forums US, les effets de bord sont ravageurs.
@Jonathan & @Dan : à la limite, ils s’en tapent. Le problème arrive quand le bruit dépasse la sphère des Power Users comme maintenant.
@Match en direct : dis en plus sur ces techniques, car blacklister un concurrent n’est pas si aisé d’après mon expérience. Autant c’était facile de dégager une page d’une requête, autant le blacklistage est une autre paire de manche.
En fait, je suis plutôt content de ne pas travailler avec Matt actuellement. L’objectif d’éradication du spam est une montagne.
Google à créé un monstre en prenant en compte le linking. Bien évidement, tout le monde s’est engouffré dedans. Surtout en France avec la part de marché qu’il a.
Ce combat me fait penser à celui de la lutte contre le spam par mail. Les canailles qui pourrissent nos boites ont toujours une longueur d’avance.
Bien évidemment, il y a toujours la solution manuelle. Vu la masse à gérer, le seul moyen serait de communiquer à outrance sur les sites qui auraient été démasqués afin de faire une peur bleue aux candidats à venir.
Un peu comme Hadopi 🙂
Ils ont des moyens ridicules, mais ils misent sur la frousse.
@Sylvain : yep MC ne doit pas avoir son sourire Colgate en ce moment.
Woow 4 commentaires et pas une seule ancre optimisée 😀 Bravo!
« Woow 4 commentaires et pas une seule ancre optimisée 😀 Bravo! »
Comme quoi la lutte anti spam fonctionne
Je crois que malgré ses énormes moyens google est incapable de lutté. Oui il va pouvoir faire certaines choses mais les spammeurs auront toujours une longueurs d’avances. Que peuvent faire 150 ingénieurs de chez google contre des milliers d’autres personnes qui ce creusent la tête pour trouver de nouveaux moyens pour spammer.
Le principal problème me semble être la force des liens.
Donner autant de force aux liens à permis à Google de devenir le moteur le plus pertinent.
Il va falloir trouver autre chose dans les années à venir… ou du moins des modèles complémentaires pour affiner et devenir moins sensible.
L’analyse des comportement des utilisateurs est certainement la clé. Mais aussi certainement très complexe et couteux…
Je ne vois pas non plus ce qu’il peut faire contre toutes les techniques black hat, je pense que tôt ou tard google va devoir tout revoir, ou alors laisser sa place à un moteur qui sera plus malin.
Oui après le bruit ne lui fera pas faire « marche arrière », au pire Google va te sortir au final « on a eu les résultats qu’on attendait contre notre lutte contre le spam… » Mais les pollueurs seront toujours là…
Commentaire censuré ?
A cause du lien ??? Dans ce cas là, ne pas mettre de dofollow, je suis joignable par email si vous souhaitez en parler 🙂
Il y a des thématiques qui ont bougé, des sites qui sont tombés, mais étrangement ce sont les bases qui ont été touchées, je rejoins Laurent vis à vis des effets de bord.
Quoi qu’il en soit, je n’arrive pas à mettre le doigt sur ce qui a été modifié.
+1 avec Aurélien : tant qu’il n’y aura pas d’analyse sémantique des pages, et que les liens auront autant de poids par rapport au contenu, le problème persistera.
On peut trop facilement positionner du contenu crado avec quelques bons liens…
Comme dit dans l’article, les internautes moyens ne sont absolument pas au courant de tout ça et trouvent ce qu’ils recherchent à travers Google. Tant que les résultats ne seront vraiment pas dégueulasses, Google n’aura pas de soucis à se faire sur sa popularité.
Alors, c’est vrai, c’est bon ? On peut continuer ? Yes !! 🙂
Point de vue très intéressant,
J’ajouterais juste, et quand GG crée la possibilité de « spam reporter » un site web non pertinent, ce sont encore les BH les premiers sur le coup…
Effectivement, du boulot en vue pour GG, et c est une très bonne chose 😉
@Monbuzz : ce ne sont pas tant les ressources d’un côté ou de l’autre, mais plutôt le concept même de Google qui a des limitations.
@Aurélien : le PersonRank sera justement le sujet de ma conférence à SEO Campus.
Faut pas compter sur de la véritable sémantique, donc le vote de popularité par le biais des actions de l’internaute est certainement salvateur. Cela dit, c’est enclenché depuis bien longtemps déjà.
@John : encore une fois, tout est relatif. Pour le Power User, Google est spammé, mais l’internaute de base y trouve son compte. Même le spam peut lui être utile en fait (genre pour acheter, etc.).
@Dan : d’accord avec toi. Je ne vois pas Google faire marche arrière.
@Paul : nope je n’ai rien censuré. Je viens de sortir 2 commentaires du bac à sable, mais pas le tien (ou alors c’est toi match en direct ?).
Si y en a bien un de cool sur la modération, c’est bien moi. On m’a même dit l’autre jour que mon blog est un « nid à spam ».
@Aurélien : franchement, je n’ai pas eu le temps de creuser plus en détails. D’autres sont bien dessus par contre.
@Daniel Roch : pour ma part, je ne crois pas que Google devienne un jour sémantique. C’est peut-être d’ailleurs son problème.
@Morgan Prive : voilà c’est le cœur du problème. Les Power Users que nous sommes représentent une tranche infiniment maigre du camembert. Peu importe ce qu’on pense; sauf quand ça fait un peu trop de bruit – genre article dans le Washington Post.
@Vince : yep à la bonne franquette 😀
@le198 : bah ça se saurait si le spam report marchait si bien. C’est vite vu car le mail est consulté dans les 2 ou 3 jours qui viennent. Donc, s’il n’y a pas de conséquence immédiatement sur les SERPS, tu peux toujours attendre.
Article intéressant, c’est certain que Google n’est pas prêt d’endiguer le phénomène, il aura toujours un train de retard.
@Sylvain : le souci, ça pourrait être de passer à la trappe un jour, sans véritable raison, pour servir d’exemple ou suite à une « erreur d’algo », alors que tu travailles globalement proprement.
Mais d’une manière générale, je trouve que google est sur une pente savonneuse :
– Échec dans les réseaux sociaux jusqu’à présent
– Index de moindre qualité
– Incapacité à lutter efficacement contre le SPAM
– Nombreuses procédures juridiques en cours
– Pratiques douteuses d’abus de position dominante avec le favoritisme de ses propres services
– Une communication moyenne de ce cher Mat qui me tape parfois sur les nerfs
– Respect de la vie privée…
On pourrait continuer longtemps. Depuis quelque temps, Google ne fait pas parler de lui qu’en bien, c’est un doux euphémisme et pas mal de services commences à lui faire de l’ombre, même s’il reste le maître du search.
Regardez MS avec IE, y a fallut changer de fusil d’épaule, parce que sinon…
Alors Google, futur ex leader de l’Internet mondial ?
Je suis 100% d’accord avec cet article sur le constat.
Apres je vais me permettre de m’étendre un peu sur le sujet.
La phrase importante qui a retenu mon attention est « Ce dernier date de 1996 avec une refonte en 2001 ». Donc déjà 10 ans sans changement majeur ou refonte complète de l’algorithme.
Ça fait un peu long non ?
Le problème de Google aujourd’hui c’est un peu le même problème que Microsoft (je suis désolé de le remettre sur la table, mais c’est flagrant).
Quand le système n’est pas ultra bordé à la base, on patch et au fil des années on patch tellement qu’on ré-écrit un système qui intègre les précédents patchs en natif => système de merde.
Prenez l’exemple d’OpenBSD, comparé aux autres OS il n’y a pas photo. Le système à été extrêmement bien conçu et pensé avant et durant sa conception.
Revenons à nos moteurs et ne mettons pas Blekko face à Google. Blekko arrive 15 ans après Google, il est donc normal que ses concepteurs prennent en compte les facteurs qui font qu’aujourd’hui Google se bat dans le vent contre le spam. Si ils ne pensent pas à ça aujourd’hui, autant dire que ça serait un moteur de merde de plus sur le web.
Donc quand MC annonce un Blekko like sur Google, mouarf mouarf mouarf. Et oui, encore un patch de plus !!
Mais la solution alors, elle se trouve ou ?
Surement dans l’informatique quantique et les IA reposant dessus. C’est en tout ça ce que défend Mr Penrose, l’ami des BH puisqu’il a découvert les réseaux de spin 😉
Si les QR de chez Google apprenait à une VRAIE IA à découvrir le spam, l’algorithme s’enrichirait automatiquement et les QR serviraient a quelque chose !!!
Mais vu l’avancée des ordinateurs quantiques et la complexité à développer sur ce type de machine, je me permets de reprendre la dernière phrase de ton article : « en attendant je ne me fais pas la moindre illusion sur le vain combat de Google contre le spam et surtout contre le contenu de basse qualité. »
Mais un point me chagrine Laurent, tu parles du contenu de basse qualité, je pense que le problème est justement là, comment le définir? Pour moi qui suit actuellement des études de psychologie en parallèle de mes activités webiennes, le site http://www.psychologies.com/ est du contenu de très mauvaise qualité, un peu comme un 20minutes voire un Voici par rapport au Monde, mais pour le surfeur lambda il y trouvera son compte de sornettes…
Et je ne pense pas que ton analyseur de « Latent Semantic Analysis » soit qualifié pour définir le contenu de « qualité » !
J’adore lire ces articles de fond qui font mal à la tête après (même si ca prend pas mal de temps).
Pour ma part, Google essaie de combattre ces méthodes en augmentant la personnalisation des résultats mais c’est hélas trop faible aujourd’hui. Google se mord la queue, s’il décide de mettre les utilisateurs dans la boucle pour l’aider dans ses résultats (comme il a pu le faire avec Google Wiki) ce sera forcément automatisable.
D’autres solutions existent pourtant : baisser la valeur d’une ancre de lien, augmenter le filtrage manuel de façon à foutre la trouille aux gens (cf commentaire de Sylvain).
Avec le pouvoir des effets d’annonces qu’ils ont ce serait assez simple.
A voir aussi pour la prise en compte du LSA, qui a été faiblement démontrée par Seomoz. Comme tu le démontres, trop faible pour en faire un classement.
H.S : Tu fait une présentation au SEOCampus ? Tu n’es pas dans la liste des intervenants ?!
RaphSEO « BH car ils utilisent « le contenu de faible qualité » à tour de bras. »
Raph les BH n’utilisent pas du contenu dupliqué, ce sont des sites bien WH qui font çà.
> Oui, Google est un peu paumé. C’est devenu un mammouth et les temps de réaction sont lents, alors que les bons tricks seo s’échangent toujours plus vite.
Laurent, quel bon article, tu fait l’unanimité là je crois 😉
@Renardudezert : c’est le principe d’un algorithme par couches. Si tu prends une formule de math, dur de changer une virgule sans tout casser. Du coup, c’est plus facile de plaquer des formules/algorithmes les unes sur les autres. Quand Google annonce 400 modifications par an sur l’algorithme, ce n’est pas la couche de base qui est concernée. Ils plaquent juste des filtres (algorithmiques) à certains endroits de l’index. D’ailleurs, 400 modifications me semble peu car chaque requête fait quasiment l’objet d’un test.
@Combat de Samuel : c’est vrai que mon propos peut prêter à confusion. Par contenu de qualité, je n’entends pas que tout soit de qualité équivalente à Le Monde. Je suggère simplement que ça ne soit pas une soupe de mots ressemblant plus ou moins à la source originale.
J’aurais du préciser cela, mais ça me semblait tellement évident dans mon esprit que je n’ai pas pensé à la confusion possible.
@Vincent : il ne fait aucun doute que Google n’utilisait pas le LSA auparavant. Depuis la mise à jour de l’infrastructure Caffeine, il est possible qu’ils fassent une tambouille maison en amont des requêtes. En tout cas, je ne vois pas ça comment un calcul en temps réel.
Après, c’est juste une bonne analyse pour voir quel type de contenu on a entre les mains. A la limite, peu importe, si Google l’utilise ou pas. Ce n’était pas mon propos. Trop nombreux sont ceux qui ont pensé trouvé le St Graal là dedans.
Hum je viens à l’instant d’envoyer ma fiche à SEO Campus. Normal que je ne sois pas encore dans la page des intervenants…
@Thibault : enfin si les BH continuent de scraper à gogo. Sinon, c’est vrai que ce n’est pas du contenu dupliqué intégral.
@Laurent : d’accord mais alors les fermes de contenu du type ehow.com produisent du contenu original non?
Ah que j’aime ce genre d’articles écrits sans mots machées… analyes et déductions sérieuses… et puis moi ca m’encourage dans mon chemin gris sombre mais pas complètement noir… Chaque SEO ayant sa méthodologie, sa technique… GG ne peut que ce mordre la queue. Faudra que je me trouve une teinte bien précise moi tien.
Cela rejoint un de tes précédents post sur blekko. On peut se demander si le problème ne vient pas du choix initial de google: l’utilisation d’algorithmes pour classer le web.
Est-ce que facebook avec sa puissance de frappe sera plus fort en introduisant le web sémantique et en utilisant tous ses membres pour trier le web?
L’analyse est très fine, et délimite les principales contraintes qui pèsent sur l’algorithme de Google du fait des techniques BH essentiellement.
Étonnamment, cela oblitère cependant un peu les très justes analyses sur le personal ranking que tu proposes habituellement, Laurent, et qui constitue cependant sans nul doute la vraie préoccupation de GG.
Car si effectivement c’est pas demain la veille que GG éradiquera l’automatisation des taches tant en terme de linking que de production de contenu, toujours plus élaborée, même sur le plan sémantique, ils savent pouvoir compter de plus en plus sur l’intermédiation sociale comme juge de paix, s’en servant à distinguer entre les contenus et les BL.
Sans doute ne sont ils d’ailleurs pas plus avancés à Mountain View dans l’intégration de la bonne formule dans l’algo, que les experts SEO eux mêmes à en mesurer de façon fiable les effets.
Mais ce qui est sûr c’est qu’ils y parviendront dès lors même que Facebook et Twitter, pour les plus essentiels, seront eux mêmes amenés à trier pour éviter l’automatisation préjudiciable au développement de leurs propres services.
Après avoir acheter les meilleurs liens, restera à acheter les meilleures powers users certes, mais ces derniers tireront avant tout leur légitimité… de leur légitimité. 😉
@Samuel : Je veux dire qu’entre un morphing automatique et du fait main type ehow.com, il n’y a pas de différence. La notion « contenu original » est à relativiser l’un comme l’autre prennent appui sur une ou plusieurs sources.
@Emile : j’ai aussi eu cette réflexion sur une gamme de teinte entre le blanc et le noir. Sujet à creuser.
@Arnaud : déjà que j’ai fait une tartine, si en plus on commence à parler PersonRank, ça risque de devenir lourd à digérer.
On va parler de tout ça très bientôt puisque c’est le sujet de la conf que je vais donner à SEO Campus.
Excellent article.
Le problème que tu soulèves est réel.
Sans analyse sémantique des résultats, impossible de positionner une page de façon juste.
Et les faiblesses sont nombreuses, entre autre le Google Bombing, avec un nombre suffisant de lien, il devient simple de positionner un site sur une requête qui peut être négative.
Autant dire que la création d’un réel moteur sémantique améliorera d’une part la qualité des résultats, et d’autre part – et surtout – l’expérience utilisateur.
@Laurent : Oui c’était moi Match en direct 🙂 Je me disais aussi que c’était bizarre, d’autant plus que mon com’ était loin d’être du spam.
Quant aux techniques de « dé-référencement » (appelez ça comme vous voulez), oui ça existe déjà.
Et elles sont finalement assez simples !
Par exemple, lorsque tu as un site concurrent qui se met en place, son NDD a de fortes chances d’être assez jeune. Là tu balances la même description et le même titre dans 5K annuaires (ou plus si besoin ^_^) et là il faudra pas plus d’1 mois pour que Google estime que le référencement est trop rapide, trop brutal => Sandbox pour plusieurs mois et sorte d’handicap à vie.
Salut Laurent et merci d’avoir pris le temps de détailler. Je suis plutôt du genre synthétique et dans mon article sur les fermes de contenus publié hier, je n’ai pas été au bout de l’analyse comme tu l’as fait mais je suis assez d’accord : l’histoire de la lutte antispam contre les content farms, c’est toujours la même comm’ de Matt, bcp de poudre aux yeux pour faire peur aux masses…
En ce qui concerne les possibilités d’amélioration de la lutte contre le spam, pourquoi Google n’avance pas plus vite sur l’analyse du comportement des internautes, notamment le suivi des liens ? Si les liens non cliqués n’avaient pas du tout de poids, cela résoudrait déjà pas mal de pb de spam, non ?
@Guillaume : nous sommes d’accord.
@Paul : Ben t’étais juste modéré et c’est le plugin Akismet qui fait la loi.
Sinon, il faut utiliser les termes justes. Blacklister veut dire sortir un site de l’index. C’est autre chose de mettre un jeune site dans la Sandbox ou faire des tours de Google Bowling.
Cela dit, je confirme que c’était beaucoup plus facile auparavant. Foi de membre de la DarkSEOTeam.
@Olivier : merci pour ton lien qui est parfaitement complémentaire à mon billet. Je l’inclus dans le corps.
C’est clair que le signal émis par l’internaute est un excellent vote de popularité, mais je n’ai pas encore vu passer de pages qui grimpaient uniquement grâce à des clics. Les techos superstars de Google sont plus calés que nous, mais pourtant ça semble tellement évident.
@Olivier … Donc Google devrait prendre en compte seulement les liens cliqués ??? Haha… cool… y’a des centaines codeurs qui vont faire un script dont le but sera de faire des clics… avec ratio quantité/heure/jours… je suis pas sur que ca soit ça a solution Monsieur
La question est sans doute bien plus de savoir qui clique qui et quoi, et par où.
Ça doit sans doute pas se mettre en place en 3mn chrono ^^
@Emile : pas si vite camarade. Encore faut-il que tes robots cliqueurs aient une identité sous la forme d’une IP profilée par Google. Le profil du visiteur/IP est clef dans ce concept. Lire un début de réponse ici http://www.laurentbourrelly.com/blog/321.php
Ce n’est pas impossible, mais ça dépasse les compétences d’un codeur du dimanche.
@Arnaud : exactement…
En effet, ce n’est pas si simple que ça, que ce soit pour les robots cliqueurs ou les moteurs de recherche.
En + de l’IP, les cookies pourraient sans doute aussi être pris en compte, non ?
Ou aussi la configuration du navigateur (savez-vous qu’on peut facilement vous identifier avec votre navigateur et toutes les traces qu’il laisse ?)
Bien sur Laurent… mais c’est techniquement très faisable… ca serai même une focntionnalité qui serai intégré dans certaines grosses machines très appréciés par nos amis aux chapeaux sombres que ca serai pas étonnant du tout. Et avec tout ce qu’il faut pour te faire croire que le cliqueur vient bien d’un endroit adéquate avec la « cible ». Perso j’ai toute confiance en nos amis russes pour faire ce genre de chose si le besoin se faisait sentir.
@Olivier : oui le cookie Google! Au départ, il y avait la Toolbar, puis maintenant les canaux d’entrée sont multiples. Même les résultats de recherche sont trackés.
@Emile : un réseau mafieux est certainement capable de ce genre de choses. Quand je vois ce genre d’entités lancer des dizaines de sites par jour avec whois, serveur, etc. différents, c’est clair qu’ils peuvent fabriquer une armée de zombies.
Seulement, nous sommes loin des centaines de codeurs qui peuvent faire un script cliqueur.
A la limite, on peux même imaginer un hangar rempli d’ordinateurs avec Automator (actions automatisées pour Mac – chais pas comment ça s’appelle pour PC) qui va simuler des actions d’internautes.
Sincèrement je pense qu’il serai plus sein pour le grand G de revoir un peu sa stratégie de domination. Je pense déjà qu’adopter une attitude de Dieu… genre … mes voies « algorytmiques » sont impénétrables… tenir un langage aussi claire que celui du plus piteux des politiciens ne peut qu’exacerber les nerfs de certains… et que je comprends très bien.
Sur le plan purement technique.. de toute manière que ce soit les adresses IP/profil des visiteurs, cookies (plus de cybercafés…? )des gens bien spéciaux trouveront rapidement les parades adéquates… et les feront payer à ceux qui veulent les utiliser bien sur
@Thibault par « contenu de faible qualité » je n’entendais pas que DC.
Je parle également de contenu qui sont sans queue ni tête pour un lecteur humain, les fameuses bouillies pour bots
Mais les BH ont bien raison, leur maîtres mots sont efficience et rentabilité. Donc pourquoi se faire Ch… à faire du contenu propre tant qu’une bouillie suffit. C’est plus rapide à mettre place et apporte son lot de plus value au site final.
Sauf à jouer la pérennité il n’y a pas d’intéret.
Merci Laurent pour ce très bon post.
A mon avis, Google possède plusieurs cordes à son arc pour lutter contre le spam : les milliers de critères de son algorithme, Google Analytics, Google Webmaster tools, la Google toolbar, et bien sûr des modérateurs/utilisateurs qui veillent sur la qualité des résultats. Cela ne suffira pas à éradiquer totalement le spam dans les SERPs, mais cela permettrait de le limiter !
Dans la classification des pages web, en plus de l’algo Google, je ne vois rien de mieux que la validation d’un site par un humain, expert dans son domaine, un peu comme sur un directory like DMOZ! qu’en pensez-vous ?
L’article vedette du jour où l’on apprend que Google met en place des scripts personnalisés pour mettre à jour les manœuvres de copiage de Bing est assez édifiant et peut être rapproché de cet article.
Surtout quand ils jurent leurs grands dieux qu’ils font pas ça d’habitude, de même qu’ils utilisent jamais les retours de la google bar ou des autres moyens de feedback, tels qu’énumérés ici pas Cédric.
N’est ce pas plutôt un joli écran de fumée, et que tout se jouerait justement dans ce domaine : un « reniflage » en règle et de plus en plus personnalisé, et sans doute relayé par des équipes de trackeurs. Vont quand même pas laisser un boulevard ouvert à Blekko^^
@Arnaud : pour ceux qui ne savent pas de quoi tu parles, voici le lien:
Bing copie les SERPs de Google.
c’est assez rigolo en effet
@Cédric : ce que tu décris est Blekko qui est justement une création du fondateur de DMOZ.
Oups, j’avais effectivement zappé le lien, et la précision utile sur Blekko aussi 🙂
Tiens je l’avais pas vu dans le temps ce billet … C’est du laurent… Dans l’absolu je suis plus ou moins d’accord GG s’est coincé lui meme, oh son update va bien faire un peu de menage mais l’impact sera negligeable compte tenu de la somme de travail a mettre en place dans la réalité. On a pu voir lors de SEOTONS comnbien les LFE et autres machines a lien sont terriblement efficaces.
La seule soluce pour GG serait de revoir completement son alog mais comme tu dis la on touche a du sérieux et cela rique de taper tres fort sur tout le monde
@cedric pour avoir était éditeur d’une rubrique sur DMOZ je peux te dire que les éditeurs sont tous loin d’être Pro dans les rubriques qu’ils gèrent. Une bonne candidature, un bon zeste de patience et tu deviens éditeur…. Ensuite au niveau de la validation…. c’est pour moi un annuaire classique avec du poids rien de plus. Un site peut-être refusé même si il est pertinent selon l’humeur de l’éditeur. Mais le débat n’est pas là… 😀
@Laurent : au final, quel est le message que tu veux faire passer ? Que Google va ramer avant d’arriver à faire plus propre ? Qu’il faut faire appel au grey ou black hat ? Ou souhaiter bon courage à ceux qui ont pris le parti de faire propre ?
@LeJuge : pas suivi ce concours, mais tes propos confirme que les méthodologies de base n’ont pas changé depuis les premiers concours en 2004.
@Dan : à partir du moment où l’humain rentre en compte, c’est une autre catégorie de problème qui entre dans l’arène.
@Marc : un peu de tout ça je suppose…
Très juste ce billet !
Malheureusement, je ne pense pas que Google reverra la pondération du critère « liens externes » à la baisse.
Quoi qu’on en dise il demeure un critère de pertinence efficace, même si des logiciels BH permettent d’en générer à l’appel.
Sans cet aspect fondamental, le classement des pages deviendrait trop aléatoire et les changements de positions trop brutaux entre deux instants T.
A moins d’un moteur sémantique bien sûr…
En attendant, soyons réaliste : sur une thématique concurrentielle il est quand même bien plus dur d’obtenir du lien de qualité en quantité, que du contenu de qualité en quantité…
Donc le spam poussé par de bons BH n’est pas près de disparaître des SERPs ça c’est sûr ! 🙂
@Monbuzz : Je pense que tu sous-estimes Google et que tu inverses un peu les rôles. Jusqu’à preuve du contraire, jusqu’à présent, c’est toujours Google qui a eu un temps d’avance et les référenceurs qui tentent de s’ajuster avec un peu de retard…
Franchement, pour moi, ce n’est pour eux qu’une simple piqure de rappel pour Google et je ne doute pas qu’ils sauront y apporter des réponses. A mon avis, ils ont anticipé depuis déjà quelques temps et testent des correctifs.
Google gagne toujours 🙂
@Nicolas Deschamp : pas mal ta citation! A laquelle je réponds « c’est le plus acharné qui gagne ».
@Blog Mode Eva : heu pas d’accord là. Tu trouves vraiment que c’est si compliqué de faire du référencement sur Google ?
C’est difficile, mais pas compliqué!
Et si l’avenir de Google était l’humain ?
Si l’orgueil de Google, qui se repose sur sa technologie, était son point faible ?
Rapidement, une illustration.
La technologie Google permet de « cerner » des sites potentiellement problématique (MFA, ferme à contenu). Cerner ce type de site par la technologie est bien plus facile que de les identifier et de les sanctionner tjs par cette même technologie.
Ensuite, pour les sites cernaient comme potentiellement problématique, 100 personnes bossant 150 par mois, vérifiant des sites « à la main », à 3 min par site (pas besoin d’aller loin pour reconnaitre une ferme à contenu ou un mfa, pensait aux call center et aux nombres de contacts/jours pour les opérateurs), c’est 300.000 sites vérifiés par mois, avec pour les sites enfreignant les critères de qualité établis par Google une sanction manuelle/humaine.
Ok, je simplifie la chose, mais l’idée est là, l’orgueil de Google l’empêche de remettre de l’humain dans son fonctionnement, courant après la technologie pour résoudre ses soucis…
Parmi les légendes urbaines, le rôle des Quality Raters a toujours été surévalué.
Car les humains dont tu parles existent bien. C’est un programme chez Google qui utilisent des personnes pour auditer les sites Web.
Sauf que l’utilisation de ces rapports pour le classement d’un site n’a jamais été démontré.
Avec l’affaire qui nous préoccupe aujourd’hui à propos des manipulation manuelle dans les résultats de recherche Google, je ne sais plus trop quoi penser.
L’autre élément en relation avec ton commentaire concerne l’indice d’autorité qui part effectivement d’un couche manuelle. Dans un premier niveau, des sites d’autorité sont choisis. Ensuite, le degré d’autorité décroît en fonction des niveaux de relations jusqu’au site d’autorité max. Après le premier niveau, le reste serait algorithmique.
@Laurent : Attention, je ne dis pas que le référencement en lui-meme est compliqué. Par contre, quand Monbuzz dit que Google est incapable de lutter, je ne suis pas d’accord. Pour moi l’ordre c’est :
1- Google optimise son algo
2- Les référenceurs subisse les « contraintes » du nouvel algo et commencent à en comprendre les détails et les « failles » potentielles
3- Google anticipe les correctifs sur ces failles et prépare son nouvel algo
4- Les référenceurs commencent à profiter de ces failles
5- Google met en place la nouvelle optimisation de nouveau son algo
…
Voilà! Pour moi c’est dans ce sens que ça se fait et non dans le sens inverse 🙂
Google modifie son Algo pour donner a chaque foi le meilleur resultats des recherches par rapport a un mot clé
google veux ce qui ce passe dans la vie réelle ce passe au meme temps dans le virtuel
Bonsoir, et merci pour cet excellent article !!
Je suis tout nouveau sur ce terrain, et google rajoute de l’huile tous les jours …
Il existe des logiciels anti virus, des anti spyware, des anti spam, pourquoi ne pas mettre d’équivalent sur les serveurs DNS qui blacklisteraient directement les fermes de spam ?
Sur ce, bonne soirée, et Googlez-bien ^^
Salut,
Merci pour ces infos, cela me permet dans le peu de temps que j’ai d’optimiser le ref de mon blog immobilier….
Cdt Bob
Je me demande parfois ce que Google inclus dans son combat contre le spam. Sans parler des sites de spam pure, je remarque que qu’ils en laissent beaucoup passer pour les sites « clean » qui procure un bon « user experience » mais qui profitent de techniques de spam de très bas niveaux pour atteindre leurs positions.
Je ne rabaisse pas à ses techniques puisque je ne crois pas et j’espère que ca ne tiendra pas à long terme mais surtout parce que c’est purement de la triche… Rand et SEOmoz en général m’inspire beaucoup pour ce qui est de link building.
Merci pour cet article enrichissant!
Gros boulot en perspective pour les ingénieurs de Google si la résolution de lutter à fond contre le spam est vraiment à l’ordre du jour.
Sinon question Laurent, auriez-vous un lien pour essayer Xrumer
Merci pour cet article Laurent et pour la preview que tu m’en as fait sur Skype 😉
Je pense que tout vois juste et il n’y a pas vraiment de solution : c’est comme le dopage dans le cyclisme.. les coureurs ont toujours une longueur d’avance, sauf que sur le web, Google ne ressort pas des échantillons d’urine vieux de 5 ans …
Le vrai problème est l’impasse dont tu parles : le off-page n’est pas pénalisable, ou alors on peut tuer ses concurrents. Et les trucs sales sont en off-page. Le black Hat SEO on-page, c’est plutôt de l’œuvre d’art (de mon point de vue), parce qu’il y a une vraie problématique de finesse des techniques pour ne pas se faire choper.
Mais bon, comme il n’existe actuellement pas de technologie meilleure que celle de google, je ne vois pas ce qu’on pourrait faire…
intéressant cette réflexion !
je rejoins particulièrement cette analyse sur un point, voici un exemple :
je considère le site comme CCM comme du spam (à mon niveau) puisque lors de recherche concernant l’informatique et dépannage, le site CCM prend bcp de place et les réponses sont souvent non pertinentes !!
le site est à un tel trust qu’il passe devant tt le reste ! et franchement ca me gave sévère !
Alors que l’utilisateur d’ordinateur moyen se contentera des réponses et n’ira pas plus loin …
Deux visiteurs deux réponses / attentes / besoins différents
Je dirai que la pertinence d’un requête passe aussi par le profil de l’utilisateur …
Par exemple, mon profil pas difficulté avec EN, FR, et informaticien …
google pourrait donc me proposer un contenu adapté à mes compétences … plutôt que de donner (balancer) des réponses qui sont « statistiquement » valables (on page) mais dont la valeur est proche de 0 (perte de temps) !
my 50 cent …
Sebastien
fiou, je viens de finir de lire l’article et il est captivant !
ce qu’on peut conclure de ton article, c’est qu’il y a de moins en moins de place pour les noobs black hat, mais que les gens malins tireront toujours leur epingle du jeu.
C’est comme pour le téléchargement : les états n’ont aucune chance et les seuls qui risquent ce sont ceux qui n’y connaissent rien.
C’est le premier article que je lis sur ce blog, et mon avis c’est que c’est loin d’être le dernier, merci 😉
Le problème reste l’algorithme de Google qui favorise le référencement par liens naturels et favorise donc le spam !
Pas la peine de flipper, il suffit d’être clean, et de savoir ce que l’on fait.
Merci de l’article, il est très intéressant. Une refonte complète de l’algorithme ne semble pas possible, mais le travail effectué est colossal. Je lève mon chapeau aux employés de google et à leur bon travail, ces imperfections ne sont que mineures.
Excellent article assez complet.
@laurent: « Car les humains dont tu parles existent bien. C’est un programme chez Google qui utilisent des personnes pour auditer les sites Web. »
C’est clair que cela serait vraiment bien que l’oeil humain prenne de plus en plus d’importance. Après, je n’y crois pas vraiment.
L’automatisation est un élément bien confortable, non ?
Et si l’on pense que Google pourrait être taxé (http://www.leparisien.fr/flash-actualite-economie/besson-pour-un-nouveau-report-de-l-application-de-la-taxe-google-24-05-2011-1464815.php)… c’est le monde à l’envers
A lire tous les avis, souvent très interressant on s’aperçoit qu’on tourne en rod … Notre ami Google a forcément un temps d’avance, puisque le sport préféré d’un réferenceur c’est de le comprendre au mieux et d’être le meilleur en restant border line sans se retrouver à cayennes pour 6 mois 🙁 Alors coninuons nos effeorts et adaptons nous, nousn n’avons pas le choix 🙂
De toutes façons, il n’y a pas 36 solutions … on fait du référencemnt propre, fastidieux agrémenter d’un contenu intéressant et mis à jour régulièrement ou on veut griller les étapes et on commence à être sur le fil avec un risque de pénalité sur un ou plusieurs mots clés ou on fait de la merde pour monter vite … mais pas longtemps! Il suffit donc de savoir dans quel camp nous sommes 🙂 on ne peut pas vivre sans lui …
Philippe
Le chose la plus facile à faire, c’est se faire pénaliser, surtout avec un site jeune. Il faut apprendre la patience et être pugnace pour être un bon référenceur, çà finit toujours par payer, si on à la chance de ne pas prendre de punition par notre Maître à tous 🙂