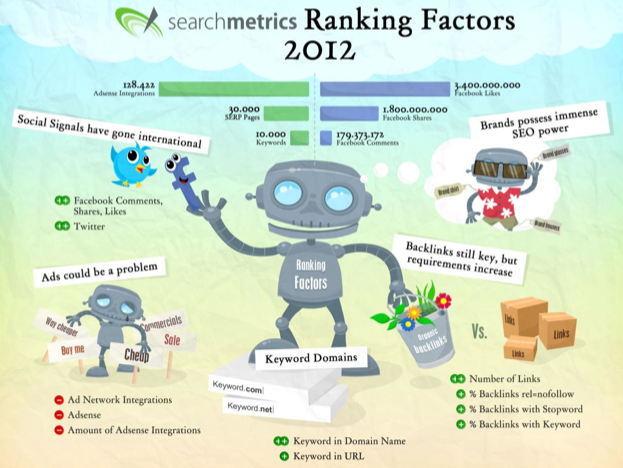
 L’étude SearchMetrics porte sur 10 000 mots clés sur 30 000 résultats de recherche, totalisant 300 000 balises Title, descriptions et URLs.
L’étude SearchMetrics porte sur 10 000 mots clés sur 30 000 résultats de recherche, totalisant 300 000 balises Title, descriptions et URLs.
L’analyse « on site » pèse 14n68 GB de données, 128 422 blocs Adsense, 179 373 172 commentaires Facebook, 1,8 milliard de Shares et 3,4 milliard de Likes.
Au niveau des mots clés, SearchMetrics a pris soin de constituer un mix représentatif capable d’extrapoler sainement.
Avant d’aller plus loin, une question très intéressante, à laquelle l’étude cite dans sa conclusion, mais ne peut pas y répondre : « un site reçoit-il des signaux sociaux parce qu’il est bien positionné ou est-ce qu’il se positionne bien grâce aux signaux sociaux ? ». J’en profite également pour recommander les produits SearchMetrics qui sont très performants, sans oublier l’équipe qui est très sympa.
Étude SearchMetrics 2012 sur le SEO en France
- Lien vers l’étude facteurs de positionnement en France pour 2012 (à payer avec un Tweet)
- Lien vers tous les White Papers SearchMetrics.
Graphique général des facteurs de positionnement
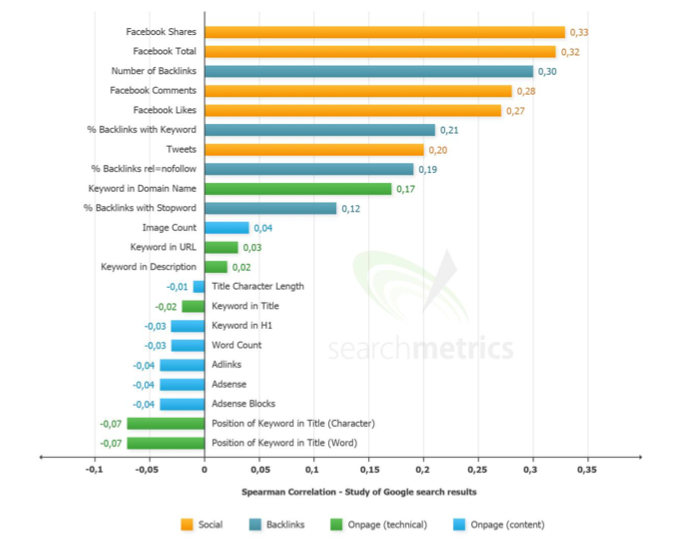
Parmi les confirmations de notions qu’on sentaient déjà, voici les principales :
- Les signaux liés aux médias sociaux : le triplé Facebook, Twitter et Google+ semblent être des consolidateurs de positionnement.
- Pub à outrance : Google l’avait annoncé officiellement, mais l’étude SearchMetrics confirme que l’abondance de publicité puisse plomber un site. Le truc intéressant est que les blocs Adsense négociés à la MFA sont particulièrement visés.
- Le levier le plus puissant demeure le backlink, mais la quantité, qui reste une valeur sûre, doit maintenant être relativisée avec un mix mieux conçu.
- Les marques d’une certaine envergure sont être traitées différemment des fondamentaux du référencement, tels que l’optimisation de la balise Title, etc.
- Les mots clés dans le nom de domaine est un levier toujours bien puissant, malgré les discussions qui suggèrent le contraire. Par contre, le TLD impacte peu.
Signaux sociaux
Tout comme pour l’étude SEOmoz des ranking factors (dommage qu’elle soit illisible comparée aux précédentes), je reste extrêmement surpris du poids de Facebook. Sans m’être particulièrement penché sur le sujet, les proportions me semblent énormes dans les deux études.
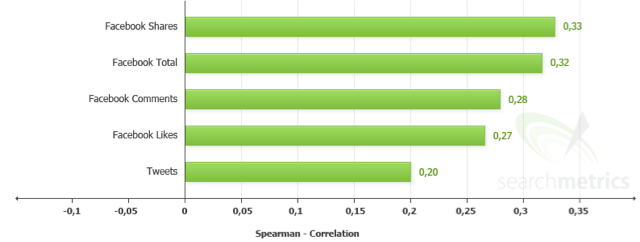
Sinon, en bref, c’est le partage sur Facebook qui semble être le plus rémunérateur, suivi de près par le Facebook Total.
Je ne m’attendais pas à voir le Tweet aussi faible par rapport au Facebook Share, mais je ne m’étonne pas du commentaire de SearchMetrics qui mesure l’influence de Google + similaire à celle de Facebook, sauf que les chiffres Google étaient trop petits pour être inclus dans le graphique.
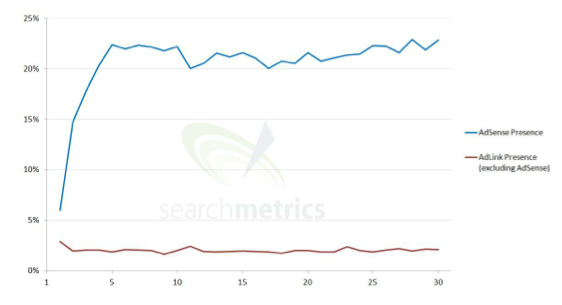
Trop de pub tue la pub
Flagrante confirmation des effets post-Panda, mais cela devient loufoque d’observer qu’Adsense impacte négativement beaucoup plus que ses concurrents. Le seul problème est que c’est le plus facile à mettre en place et qui paye sans doute encore le mieux.
Pour aller plus loin, c’est même Adsense qui serait le seul réel Red Flag.
Le roi backlink chahuté
La puissance du backlink est outrageusement démesurée, mais c’est le point différentiel de départ si on remonte à la création du moteur. Ce coup de génie est aussi son talon d’Achille qu’il s’est finalement mis à traiter plus finement. Tout du moins, faire croire qu’il y arrive.
Problème déjà établi avec Panda et maintenant renforcé avec Pinguin, donc un peu plus de subtilité s’impose.
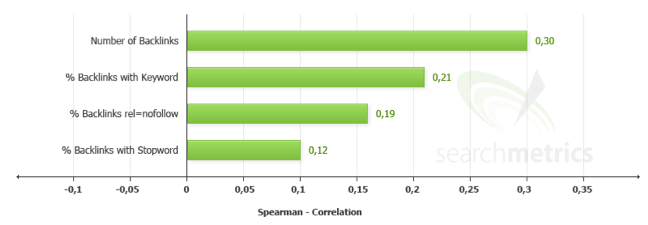
Le bon sens est le meilleur atout pour composer un profil de liens qui tienne la route. C’est un sujet que j’ai traité à plusieurs reprises, mais je vais tâcher de revenir à nouveau sur ce point crucial des actions de référencement.
Le poids de la marque
Finalement, je suis persuadé que le secret du référencement tient dans la constitution d’une marque. L’analyse SearchMetrics confirme fortement cette idée. Lisez bien ce passage car il est surprenant.
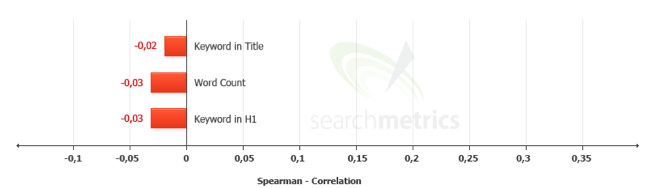
Reste à se pencher sur tous les éléments qui vont contribuer à créer une marque. Le débat est déjà en cours, mais un sérieux état des lieux s’impose.
Nom de domaine
Malgré les affirmations de Google, les mots clés dans le nom de domaine restent puissants. Bien sûr, le poids du mot clef dans le nom de fichier est marginal.
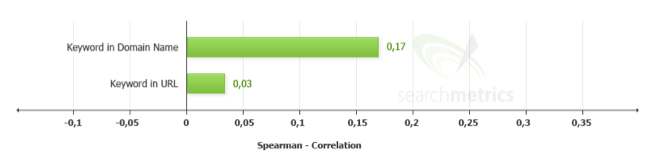
J’aurais aimé plus de détails sur l’étude, notamment par rapport aux formats des noms de domaines. Par exemple, est-ce que les noms de domaines avec tirets (surtout les trois tirets et plus) s’en tirent aussi bien que ceux sans tirets ?
Plus étonnant, le TLD n’apparaît pas déterminant. Le .FR donne un petit avantage évident, mais pour le reste ce n’est pas important.
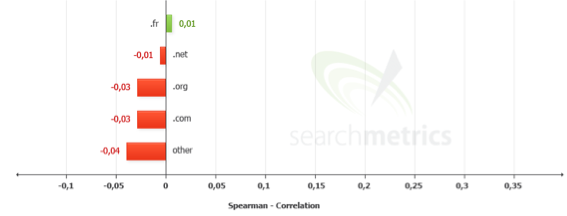
Facteurs additionnels
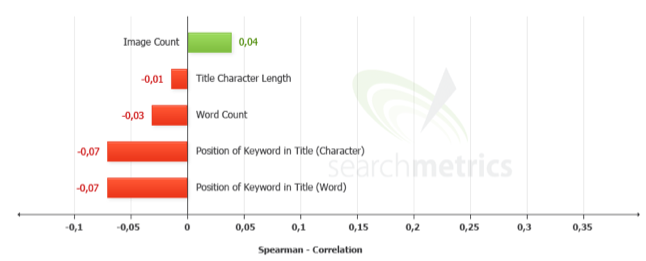
Quelques autres trouvailles suggèrent que l’ajout d’images est un signal intéressant. C’est à relativiser, par rapport au rapport indirect avec les médias sociaux, mais c’est plutôt des paramètres en baisse que les résultats surprennent.
Par exemple, un texte trop long serait préjudiciable ou que la balise Title fait l’objet de toutes les attentions, chez Google, afin de la décortiquer du mieux possible.
Quoi conclure ?
Beaucoup de confirmations et quelques surprises dans cette étude. Comme d’habitude, les données sont à prendre avec toutes les précautions qui s’imposent; notamment sur le fait qu’on ne peut pas faire un reverse engineering depuis des observations sur l’interface Google. Notre bonne vieille méthode empirique et le flair sont toujours à mettre en priorité dans les choix.
En tout cas, cela me conforte sur le travail que je mène personnellement dans le sens d’un renfort de marque.
Je suis impatient de lire vos remarques et tâcher de participer activement à la discussion.
En passant, toutes mes excuses pour certains billets où je n’interviens pas trop dans les commentaires, mais je lis tout.
Bonjour Laurent,
Effectivement, ces études montrent la nécessité de s’appliquer à travailler sur la constitution ou le renforcement d’une marque ainsi que sur la notoriété d’un domaine.
amicalement
Un élément n’a pas été abordé dans cet article, mais on remarque sur la première image que les liens nofollows sont quasiment aussi important que les liens follows.
Un début de preuve que ces liens sont très important dans le mix SEO ?
Moi je suis plutôt étonné de l’effet « images »
J’ai toujours entendu qu’il fallait au contraire un haut taux texte/reste.
Ça devient difficile de donner une sémantique si on optimise ni URL, ni h1 … Même le title est en négatif je comprends pas trop la sur le coup
@Yoann personnellement j’ai toujours été convaincu de l’intérêt des liens Nofollow. Pas dans le sens où ils permettraient de ranker, mais dans celui où ils évitent d’envoyer un signal négatif à Google.
Le nofollow fait partie d’un profil naturel
pour le restant c’est plutot cohérent même si certaines choses m’interpellent (texte trop long…)
Salut Laurent,
merci pour les infos.
Curieux, rien sur la taille du contenu d’une page. De mon côté, j’ai souvent observé que si tu avais une page avec 1000 mots, elle était plus facile à positionner qu’une page de 100 mots (à densité de kw comparable)…
Rien non plus sur le poids de RT dont il me semble qu’ils comptent bien plus que le tweet de départ.
Je suis par contre heureux de voir confirmer que le BL, utilisé en finesse, a toujours son importance 🙂
bat
Christian
@Ralf : Je pense comme toi pour le nofollow, c’est pourquoi je parlais de « début de preuve ». Concernant le texte trop long, je suis également très surpris…
@Lionel : le favoritisme associé mérite clairement de s’en donner la peine. A tous niveaux d’ailleurs.
@Yoann : c’est implicite dans ma remarque. Le nofollow fait bien évidemment partie d’un profil de liens sain. J’en recommande même une dose de 50%.
@Bijoux : pour moi, l’élément image et son alt associé ne sont pas super influents en tant que tels, mais ils sont de très bons renforts au reste et à la Title en particulier.
@Raph : les résultats manquent de détails. On préconise 300 à 500 mots, mais je ne sais pas si c’est considéré comme court. Je vais leur demander.
@Christian : vu le poids du Tweet, j’ose supposer que le RT est encore moins influent.
Je suis étonné que nulle part dans ton article Laurent tu n’écrives en ENORME « corrélation ne signifie pas causalité ».
Pourtant ça éviterait à pas mal de monde de tirer de nombreuses conclusions totalement fausses.
Cette étude montre les habitudes de ceux qui sortent bien dans Google.
Ca ne montre nullement pour quelles raisons ils sortent bien.
Par exemple même le JDN titre « Pas besoin de mettre le mot clé en titre pour bien se positionner ? » (et encore je crois qu’ils ont ajouté le « ? » après mon commentaire).
Il n’en reste pas moins que cette étude est très intéressante notamment de part le volume des données traitées.
@Laurent, pas forcément, GG peut traîter l’un en ignorant l’autre, ce serait bien son style 😉 ce d’autant, qu’un RT semble plus naturel. mais bon, on ne sait pas, mais cela aurait été bien qu’ils l’intègrent dans l’étude justement
Tu as eu raison de croire dans ton podcast (et preuve à l’appui dans cet article) à l’importance des mots clés dans le NDD.
« Les mots clés dans le nom de domaine est un levier toujours bien puissant »
Bien évidement, j’ai fait un test très simple là dessus, j’ai acheté un domaine, je l’ai gavé sur la thématique de celui ci, sans Backlink de ma part, juste quelques flux repris par de bons sites, le domaine, je ne vous le donne pas, mais tapez sur Google « business wordpress » vous verrez que malgré la concurrence sur ce sujet, il ne m’a suffit que de respecter la thématique de mon domaine, puisqu’il est évident qu’il en comporte une, et celui ci se positionne, sachant que le site n’a VRAIMENT aucun jus. ous reconnaitrez ma frimousse dans les résultats GG.
Merci beaucoup Laurent ! Toujours un plaisir de lire tes messages! Je ne pensais pas que les keywords dans l’url était important !
A propos de keyword dans title et H1 c’est pénalisant de mettre un keyword dedans pour une requête ciblé ?
Très surpris par cette étude.
Premièrement, je pensais que l’impact des mots-clé dans le nom de domaine devait diminués… Il est en fait toujours très important.
Deuxièmement, les signaux sociaux sont en fait incroyablement importants. Je me pose donc une question : comment fait-on lorsque l’on vend des crochets de levage par exemple ? Il n’en ressort absolument aucun caractère social (en tout cas pas le social lié à Facebook)…
@RestoManiak, « comment fait-on lorsque l’on vend des crochets de levage par exemple ? »
dans ce cas là, tu t’en fous (si tes concurrents sur les kw sont absents des réseaux).
Merci pour cette étude.
Si quelques uns de ces chiffres me confortent d’autre m’étonnent et me font même sourire:
Un effet négatif des mots clés dans le title de la page et h1 ?
C’est sûr que pour décrire au mieux une page, sans dire ce à quoi elle doit correspondre, c’est challenge.
Même si je trouve louable une telle étude, et surtout le temps qu’elle a pris, je trouve que ce n’est malheureusement que du vent.
Ceux qui font ou on fait des études statistiques le savent bien : un indice de corrélation inférieure à 0,5 n’est absolument pas pertinent et révélateur d’une tendance. A partir de 0,8, là on pourrait affirmer qu’il s’agit d’un réel critère de positionnement.
Il est donc fort dommage que SearchMetrics n’ait pas donné des indices de corrélations conjoints, par exemple un indice pour les sites qui utilisent à la fois le Title de la page et le H1, ou qui cumulent un grand nombre de votes sur Twitter, Facebook et Google+.
@Olivier : tu as raison ! J’ai hésité à traduire littéralement cette phrase, puis ensuite j’ai tenté d’exprimer autrement dans la conclusion avec mon histoire de reverse engineering.
@Christian : je promets de demander directement à mes contacts chez SearchMetrics.
@Rodrigue : perso, je crois qu’un nom de domaine bien mené est un élément super intéressant. Maintenant, je pèse toujours les avantages des mots clés et la reconnaissance de marque.
@Musculation : Les keywords dans l’URL ne sont pas importants! Leur poids est marginal. C’est dans le nom de domaine que ça dépote – pas dans le nom de fichier.
Attention également à la différence entre « pénalisé » ou « filtré » et « non valorisé ».
@RestoManiak : j’ai fermé mon compte Facebook (trop de mélange entre le perso et le pro, ainsi que ma culture en France et aux USA), puis je n’utilise pas les boutons de vote. Pourtant, je t’assure que tout marche très bien.
@Daniel Roch : je vais transmettre également la remarque.
Bonjour, seconde fois que je suis modéré… Je ne comprends pas vraiment pourquoi. Mon commentaire n’était pas moins intéressant que certains.
Pourrais tu au moins me dire pourquoi ?
merci 😉
edit… bon, comprends pas, cela à dû bugger…
Je disais donc qu’il faut faire attention à ce chiffres. Ces indices sont comme l’a très justement dit Daniel, si faibles qu’il est peu évident (voire même erroné) d’en tirer des conclusions. Quand je vois les résultats pour les des pages . …
Ton message était dans le bac à sable d’Akismet.
Regarde du côté de l’algorithme ngram ou d’autres pour voir comment ce n’est pas la peine de répéter le mot clé à outrance pour faire comprendre de quoi il s’agit. Au contraire, c’est à l’aide de co-occurences, etc.
Suis je le seul à me demander qu’elle est la différence entre « Facebook Like » et « Facebook Total »?
il y a une différence entre répéter à outrance un mot clé et l’info que donne searchmetric: Indice de correlation négatif pour l’utilisation de mots clés dans le title… Ce n’est pas « utilisation à outrance du mot clé », mais bien « utilisation tout court’.. non ?
La balise H1 par ex, peut très bien être renseignée de co-occurences, sur ce point pas de soucis. Mais quand même, c’est le titre de la page dont nous sommes en train de parler
Merci des infos, mais effectivelment attention à la valeurs des indices statistiques et des corrélations effectuées (ou pas). A-t-on accès à (ou y’a t-il eu) des tests multivariés un peu plus poussés avec les différents paramètres pris en compte?
Le cas du nom de domaine m’interpelle notamment : quand des sites s’ouvrent autour d’une nouvelle thématique, les ndd avec mots clés concurrentiels realtifs à cette thématique sont les premiers achetés (de type « nouvelle-thématique.com/fr etc.. »), et sont ainsi les plus anciennement représentés sur le web. Il est donc légitime de se demander si leurs bons positionnements ne proviennent pas plutôt de cet état de fait (et ce d’autant plus que les pionniers ont bénéficié pendant longtemps d’une forte évaluation positive des keywords dans leur ndd avec tout ce que cela entraîne).
@MCH : le total compile shares, likes et commentaires.
@Tim : envoie moi un mail si tu veux qu’on discute de ça sur Skype ou autre. Ca ira plus vite de vive voix.
@Super : à voir les études par SEOmoz. J’ai relayé quelques unes sur ce blog http://www.laurentbourrelly.com/blog/tag/seomoz
Bonjour Laurent, j’ai utilisé ton image dans mon dernier billet de blog. J’espère que ça ne te dérange pas.
Si ça te pose un problème, fais le moi savoir, je la retirerai.
A bientôt
Bonjour Laurent et merci pour ta vision.
Hier j’étais tombé sur l’article du JDN et ça ne me parlait pas autant.
A la lecture de ces chiffres, je pense que certains proposant des like et autres partages pour des sommes ridicules vont faire un peu d’argent dans les mois à venir.
Dommage que l’étude ne soit pas réalisée en post manchot et panda xxxx, on n’en saurait un peu plus sur le poids des liens après la tornade.
Bon cela dit, on peut constater que ceux qui ont toujours travailler le profil naturel dans les liens, même avec un nombre de liens totalement hallucinant s’en sortent plutôt bien.
Je suis curieux de voir ce qui fait l’identité d’une marque sur le web, c’est là que j’ai peur des réseaux sociaux et de leur signal temporaire mais gravé dans l’historique d’un site.
Finalement pas de grandes surprises.
Mais je suis impressionner par le poids des médias sociaux et leur influence.
Ce qui me donne à penser qu’il pourrais y avoir un passage des efforts du SEO pure et technique vers du médias social.
En revanche je suis surpris de ne pas voir apparaitre des surprise comme la perf.
Bonjour Laurent,
Finalement la mauvaise serait d’écrire pour les moteurs de recherche, non pour ces lecteurs. La fait qu’ils partagent confirment finalement la pertinence et l’intérêt de l’article, qui renvoie à google une justification de meilleur positionnement. (certains tests sur un même mot-clé mais différents partages seraient intéressant à mener…)
Ta réflexion sur la notion de marque est très intéressante, mais elle est aussi pour moi lié à la notion d’autorité du site, non ?
J’avais déjà lu l’étude en anglais, mais traduite et commentée avec style par un esprit critique, c’est d’autant mieux !
Sur la marque, l’augmentation de son importance semble évidente quand on voit l’évolution d’affichage des title du mois dernier qui fait apparaitre quasi systématiquement la marque ou le ndd en fin de titre dans la SERP, quand elle ne remplace pas entièrement le titre d’origine.
C’est d’ailleurs AMA ce qui fait la force persistante des EMD: même si google a modifié son algo pour ne plus donner autant de poids aux mots contenus dedans directement, il n’en reste pas moins que l’ensemble des matraquages de liens non optimisés sans ancres dans les citations « naturelles » ou dans les spams de basse qualité crée une association puissante entre les mots contenus et le site qui doit être perçue comme la marque du site, et indirectement le mettre en avant sur l’expression.
Au passage, l’article parle de l’importance du nofollow pour « naturaliser » le profil, mais j’aurais aimé avoir des stats sur la proportion de liens sans ancres dans les profils des leaders, aussi.
Un autre facteur non couvert est le taux de contenu nouveau d’un site. J’ai l’impression que l’effet fraicheur est plus fort que jamais, et qu’il rejaillit maintenant comme signal panda sur l’ensemble d’un site, pas seulement sur la page créée ou modifiée.
Bref, article searchmetrics passionnant, surtout concernant le paragraphe sur l’inversion des critères « title/h1/densité », mais il manque plein de choses, pour moi.
Allez on en cause autour, et ça mérite bien ce bait.
Bonjour et merci bien pour ces infos.
C’est toujours intéressant des études de cette ampleur.
A part la longueur du texte, alors qu’on nous parle sans cesse de contenu, rien de bien surprenant.
Les réseaux sociaux poussent. C’est intéressant d’intégrer le « facteur humain » dans l’algo des robots.
Mais ce matin encore je reçois une offre pour 1000 à 5000 fans ou followers en 48 heures…
Tiens tiens, ça me rappelle l’époque des backlinks à outrance…
@Graphemeride : l’image appartient à SearchMetrics, mais on peut l’utiliser.
@Pierre : il y a bien des dommages collatéraux. En plus, j’ai l’impression qu’ils sont plutôt nombreux.
@Sasha : les fondamentaux marchent toujours; ils ont toujours fonctionné parfaitement. Ce sont les raccourcis qu’on a pris qui se rallongent. A l’époque de la composition des fondamentaux, il n’y avait pas de réseaux sociaux comme aujourd’hui.
@Yvan : j’avais pondu un billet sur les notions de popularité, notoriété et autorité. Les 3 sont effectivement liées afin de composer un profil intéressant.
@Mathieu : je peux seulement te donner mon ratio. Sur un mot clé considéré concurrentiel, je place 70% des ancres pour diluer le signal. C’est à dire n’incluant pas le mot clef du tout; les co-occurrences sont souhaitables, mais il faut aussi aller plus loin. Par exemple, les champs pseudo des commentaires de blogs sont un élément parfait pour diluer le signal. Au lieu de coller vos foutus mots clés, gardez un pseudo ou le ndd.
@Stéphane : tiens fais ton marché 😀 http://www.seoclerks.com/
Une bonne communication hors web avec une mise en avant du site à chaque fois permettra aussi de faire mouche dans la tête du prospect. La pub peut aussi s’afficher dans un second temps. On laisse l’internaute se fidéliser, et une fois que c’est fait, on peut lui présenter quelques publicités judicieusement choisies.
Bonjour
Surprise, non ??
Outre la contradiction entre CORRELATION & CAUSALITé relevée par Alex @referencement et @rochdaniel
Les TITLEs et autres META sont moins DIFFERENCIANT, parce que nous les avons optimisés sur la plupart des sites en compétition sur les SERP et particulièrement en 1ere page.
Essayez donc de faire des LIKEs et des Tweets avec le meme TITLE identique sur toutes vos pages et vous me direz si la corrélation tient toujours.
A force de sortir en boîte (Facebook), on oublie qu’il faut quand même respirer aussi et pendant(TITLEs) 😉
Du coup, les LIKEs et les Tweets se retrouvent en 1ere ligne pour faire la différence.
Nous négligeons trop le facteur Temps/Timing/Evolution dans nos analyses.
Nous sommes trop Intant T
Soyons Long Time comme nous sommes Long Tail.
David Cohen @SEOEuro aussi
Merci Laurent pour ce retour 🙂
Je me permets de complèter une légère information concernant l’ancienne version du rapport SeoMoz, voici le lien du « Ranking Factors de l’époque :
Cf : http://web.archive.org/web/20110209045111/http://www.seomoz.org/article/search-ranking-factors#negative-ranking-factors
Salut Laurent,
Hormis une petite remarque initiale, je te trouve d’une grande mansuétude vis-à-vis de cette étude 😉
Personnellement, je trouve ce type d’étude inutile et contre-productive, car instinctivement on fait un pont entre corrélation et causalité, or c’est une erreur de le faire.
Cette étude ne mérite clairement pas son buzz et j’aurai espéré bien plus d’une entreprise comme Searchmetrics.
Mon avis complet http://ow.ly/bzrDc
Bonjour,
L’étude est très intéressante mais le poids des différents critères me semble erroné !
Comment est ce qu’un share Facebook peut-il apporter autant ?
Je pense que ce critère a été surévaluer et certains mis de coté.
D’après mes expériences, le nom de domaine, les mots clé dans les URLs, les balises titles optimisées ainsi que des backlinks bien pensés et bien placés font beaucoup pour le positionnement d’un site.
Rien de bien nouveau la dedans, par contre la future dimension sociale du web est indéniable mais quel sera l’impact ?
Difficile à prédire.
Cdlt
Une confirmation que les classiques ont toujours leur place 😉
Salut Laurent,
Merci d’avoir partagé avec nous cette étude. Je trouve que différents éléments sont intéressants à prendre en considération surtout pour les sites qui se lancent. Je pense notamment aux publicités dans tous les sens. Pour moi, un site qui affiche des publicités en popup devrait automatiquement se manger des points en moins tant c’est gênant pour l’utilisateur.
Intéressant ce résumé de l’étude de Search Métrics. Mais comme jeremy, j’ai l’impression que l’impact social à été surévalué et comme lui, je trouve que parfois les indices de corrélation sont trop faibles pour pouvoir tirer des conclusions.