 Le sujet des entités nommées est au centre du débat sur le Web sémantique. L’achat de MetaWeb par Google relance l’enjeu qui consiste à associer une entité à une référence.
Le sujet des entités nommées est au centre du débat sur le Web sémantique. L’achat de MetaWeb par Google relance l’enjeu qui consiste à associer une entité à une référence.
Il y aura peut-être des implications pour le référencement, mais elles seront largement bénéfiques.
L’achat de MetaWeb par Google
Google devient plus perfectionnés par rapport à la compréhension des entités nommées avec l’acquisition de la société MetaWeb qui a construit un système d’indexation intégrant le concept d’entité nommée.
C’est par le biais de l’insatiable Bill Slawski que j’apprends la nouvelle aujourd’hui.
Qu’est ce qu’une entité nommée ?
Tout simplement, une entité nommée peut être une personne, un endroit ou autre chose qui sera associée à un numéro d’identification unique. L’entité peut intégrer un mot ou un groupe de mots.
C’est un peu comme une classification des ouvrages dans une librairie ou n’importe quelle base de données. L’intérêt est évidemment au niveau de l’indexation et de l’identification qui pourront être mieux ciblés par ce biais.
En associant une entité avec un numéro, la recherche d’information peut se révéler plus efficace. C’est par exemple très utile lorsqu’un même terme relève plusieurs significations. De même, les noms propres sont bien mieux traités grâce au système des entités nommées et Bill Slawski cite une étude Microsoft faisant ressortir que 20 à 30% des requêtes sont des entités nominales et 71% des requêtes contient une entité nominale.
Pour en savoir plus sur les entités nommées, je renvoie vers la présentation de Jean Véronis lors de SEO Campus 2010.
Entités nommées par Jean Véronis
MetaWeb
La société MetaWeb a été rachetée par Google récemment comme évoquent les posts du blog Google et celui de MetaWeb.
La technologie de MetaWeb peut se découvrir au sein de FreeBase qui rassemble plus de 12 millions d’éléments et que Google souhaite préserver à la disposition de tous.
Voici une vidéo (en anglais) qui introduit le principe de la technologie MetaWeb
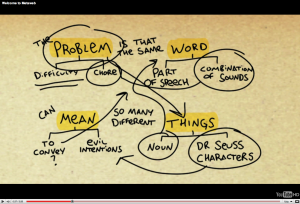
Quel est le potentiel ?
En fait, cela dépend des possibilités d’intégration dans l’algorithme du moteur de recherche Google.
L’impact peut être relativement important car le problème des termes qui représentent plusieurs significations fait partie des challenges les plus importants pour la recherche d’information.
Dans tous les cas, c’est une prise de partie franche de la part de Google puisque le Web sémantique est toujours en manque d’une norme d’étiquetage définie.
Encore une fois, la raison du plus fort fera peut-être pencher la balance; tout en sachant que la technologie MetaWeb fait l’objet de plusieurs brevets. Le concept Open Source me semble plus approprié afin de légitimer la propagation du système.
Pour le référencement, ça serait très utile de savoir sur quoi compter pour valoriser ce type d’éléments car les diverses tentatives de standard sont plutôt improbables jusqu’à présent.
A défaut de système universel, on pourra au moins savoir comment s’adresser au leader des moteurs de recherche.
C’est très intéressant, mais pour reprendre l’exemple de la requête : « orange », avec un seul mot-clé, Google pourra difficilement en déduire le sens réel et donc l’affichage n’en sera pas amélioré. Le principal problème n’en demeure pas moins entier.
Je te remercie pour cette info, difficile d’imaginer aujourd’hui toute les répercussion, mais ma crainte est que l’on aille encore vers un web, ou les plus petits, les outsider ont de moins en moins leur place.
Puisque un mot seul devras être rattache à une entité, probablement la plus courante.
@Aurélien : l’utilisation me semble difficile à mettre en place pour tous les termes. Il faut plutôt penser à « Barack Obama » ou la « Tour Eiffel » qu’à « orange ».
Sinon, je te suis dans le raisonnement. Mon premier gros travail de référencement en 2003 concernait le département du « Lot » avec tous les autres sens que le terme peut prendre.
@sacha : on peut effectivement voir l’angle réducteur, mais les bénéfices sont assez nombreux pour pousser à ce type de technologie.
Cela fait des années qu’une foule d’acteurs différents cherchent un moyen automatisé de capter l’essence sémantique d’une phrase ou d’un mot au milieu d’une phrase.
Le « concept » de dire qu’une fois parvenu à ce tour de force phénoménal, on appose un numéro unique type md5… C’est limite nul de le dire et encore plus de l’annoncer avec tambour et paillette.
Pour un programmeur ca parait un peu logique, si on étudie les moyens existant d’y parvenir ou simplement si on cherche à imaginer comment faire. On se rend compte que l’ordinateur qui aura réussit à déterminer le sens des mots, aura « simplement » effectuer une série de condition « si …, si … si… ». Ce qui toujours pour l’ordinateur, se traduit par des 01001 binaire (1 la condition est vraie, 0 elle est fausse).
Alors dire que après être parvenu à trouver l’algorithme tant attendu on va faire un md5 sur cette suite binaire et que ca c’est un nouveau concept qui vaut de l’or, je ne suis pas d’accord. Le concept est bien antérieur, et on y est pas encore parvenu, mais c’est en bonne voie (programmation type réseaux neuronaux).
Google utilise déjà le md5 ou tout du moins une version perso. La nouvelle manière de gérer le cache en est le témoin (l’URL est juste à titre indicatif).
Du coup, si un système est utilisé à l’échelle d’un moteur de recherche tel que Google, je pense qu’on peut clamer qu’il s’agit d’une application à large échelle.
LA question que je me pose moi c’est plus comment va-t-on indiqué que l’on veut que tel ou tel term soit associé a telle ou telle entité, meme si je pense que GG devrait pouvoir faire la quasi totalité du tri par lui meme.
Tout entité aura une référence.
A voir si GG va nous donner accès à ces références; sinon ça ne peut pas marcher.
Afin de vraiment tester, vous auriez à prendre le même site, changer la densité des mots clés, et de voir de quel côté il se déplace. C’est un peu trop anecdotique.
Déjà je pense que lorsque que quelqu’un tape le nom de son site ça fera office de backlink, exemple si je tape « assurances.info » il est clair que c’est l’équivalent d’un lien. Quel poids donner à ces « faux liens » ? Google trouvera bien le poids idéal de toute façon.
A l’heure actuelle beaucoup citent des noms, des domaines, etc. Sans faire de lien pour pas perdre de « jus », ces temps-là sont terminés.
J’ai jouer la présentation mais sincèrement je n’y comprends absolument rien. Mais je pense qu’avec plus d’explications plus claires, on n’y arrivera.
Merci